Looking to automate tasks on UNIX systems? Look no further! The answer lies in the powerful tool known as a UNIX cron job. This simple yet efficient tool allows you to schedule and automate repetitive tasks, saving you time and effort. Whether you need to run a script, update a database, or perform regular system maintenance, a cron job is the solution you’ve been searching for. In this article, we will delve into the concept of cron jobs, explain how they work, and provide practical examples to help you harness their full potential. So let’s dive right in and explore the world of UNIX cron jobs together!

Understanding Unix Cron Job
The Unix cron job is a powerful and essential tool for automating tasks on Unix-like operating systems. It allows users to schedule recurring tasks or scripts to run at specific intervals, reducing the need for manual intervention and improving overall efficiency. In this article, we will delve into the details of Unix cron job, covering its purpose, syntax, usage, and best practices.
What is a Unix Cron Job?
A Unix cron job is a time-based job scheduler that runs on Unix-like operating systems, such as Linux, macOS, and FreeBSD. It takes its name from the “cron” daemon, which is responsible for executing scheduled tasks at predefined intervals. These tasks are often shell scripts or commands that perform a variety of actions, including backups, log rotations, system maintenance, and data processing.
The cron job scheduler uses a specific syntax to define when and how often a task should run. It operates by reading a crontab (cron table) file, which contains the schedule and commands for the various jobs. Each user on a Unix system can have their own crontab file, allowing them to schedule and manage their own tasks independently.
Cron Job Syntax
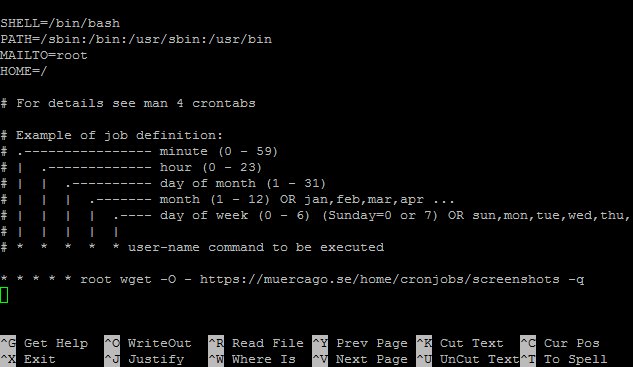
The syntax for defining a cron job consists of five fields, followed by the command or script to be executed. The five fields specify the minute, hour, day of the month, month, and day of the week when the task should run. Here is the general structure:
“`
* * * * * command
“`
Each field can take a range of values or specific values, separated by commas or hyphens. The asterisk (*) signifies any value, allowing for wildcard specifications. Here are the possible values for each field:
– Minute: 0-59
– Hour: 0-23
– Day of the month: 1-31
– Month: 1-12 (or names such as “Jan,” “Feb,” etc.)
– Day of the week: 0-7 (0 and 7 are both Sunday, or names such as “Sun,” “Mon,” etc.)
For example, a cron job that runs every day at 3:30 PM would have the following syntax:
“`
30 15 * * * command
“`
Common Uses of Unix Cron Jobs
Unix cron jobs are incredibly versatile and can be utilized for a wide range of purposes. Some common use cases include:
- Automated backups: Regularly backup critical files or databases to ensure data safety.
- System maintenance: Perform routine maintenance tasks like log rotation, updating software packages, and disk cleanup.
- Report generation: Generate daily, weekly, or monthly reports for monitoring system metrics or business analytics.
- Data processing: Process large data sets, trigger data migrations, or extract valuable insights periodically.
- Task scheduling: Schedule recurring tasks such as sending email notifications, updating website content, or running automated tests.
These are just a few examples, and the possibilities are endless. Unix cron jobs provide a flexible and efficient way to automate repetitive tasks, freeing up valuable time and resources.
Best Practices for Unix Cron Jobs
To ensure the smooth execution and reliability of cron jobs, it is crucial to follow best practices. Here are some recommendations to keep in mind:
1. Use absolute paths:
When specifying commands or scripts within a cron job, always use absolute paths to ensure the correct execution. Cron jobs run without the regular environment variables, so using absolute paths prevents any ambiguity.
2. Redirect output:
By default, the output produced by a cron job is sent via email to the user who owns the crontab. To avoid filling up the mailbox, it is advisable to redirect output to log files or /dev/null if not required.
3. Test commands:
Before adding a new cron job, it is good practice to test the command or script manually to ensure it works as expected. This helps identify any potential issues or errors before the job runs automatically.
4. Avoid overlapping jobs:
If a cron job takes longer to execute than the specified interval, it can overlap with subsequent runs, causing performance issues or conflicts. Make sure to design your jobs to complete within the defined timeframe or introduce appropriate safeguards.
5. Regularly review and update:
As your system evolves, the requirements for cron jobs may change. Regularly review and update your cron jobs to ensure they remain relevant and aligned with your current needs.
6. Keep log files:
Maintaining a log file for each cron job enables easy tracking and troubleshooting of any potential errors or issues. It provides visibility into the execution history and helps diagnose problems more efficiently.
7. Beware of security risks:
Cron jobs execute with the permissions of the user who owns the crontab. Be cautious when executing commands with elevated privileges and ensure proper security measures are in place to protect sensitive information.
Unix cron jobs are an indispensable tool for automating tasks on Unix-like systems. By harnessing the power of cron, users can schedule and execute recurring jobs with ease, improving efficiency and reducing manual efforts. Understanding the syntax, common use cases, and best practices ensures the successful implementation and management of cron jobs. Embrace the automation capabilities of Unix cron jobs and simplify your system administration tasks today.
Linux Crash Course – Scheduling Tasks with Cron
Frequently Asked Questions
What is a Unix cron job?
A Unix cron job is a time-based scheduling feature in Unix-like operating systems that allows users to automate commands or scripts to run periodically at fixed times, dates, or intervals.
How do I create a cron job in Unix?
To create a cron job in Unix, you can use the “crontab” command followed by the appropriate options and timing specification. For example, to edit the cron jobs for the current user, you can use the command “crontab -e” to open the user’s crontab file in the default text editor.
What is the syntax for specifying the timing of a cron job?
The syntax for specifying the timing of a cron job consists of five fields: minute, hour, day of the month, month, and day of the week. You can use specific values, ranges, wildcards, or special characters to define the desired timing. For example, “0 * * * *” represents running the job at the beginning of every hour.
How can I view the existing cron jobs in Unix?
You can view the existing cron jobs in Unix by using the “crontab” command with the “-l” option. It will display the contents of the current user’s crontab file, which contains all the scheduled cron jobs.
Can I edit or remove a cron job once it is scheduled?
Yes, you can edit or remove a cron job once it is scheduled. To edit the existing cron jobs, you can use the “crontab -e” command to open the crontab file, make the necessary changes, and save the file. To remove a cron job, you can use the “crontab -r” command to remove all the scheduled cron jobs for the current user.
Final Thoughts
A Unix cron job is a powerful tool that allows users to schedule and automate recurring tasks on their Unix-based systems. With Unix cron jobs, users can easily manage a wide range of tasks, such as running scripts, executing commands, and performing system maintenance. By defining the desired schedule and specifying the task to be performed, users can ensure that their systems run smoothly and efficiently without manual intervention. Unix cron jobs offer flexibility, reliability, and time-saving benefits for both individuals and organizations. With their user-friendly interface and wide range of functionality, Unix cron jobs are an essential feature of any Unix-based system.